Exemplo:
create table funcionarios
(
codigo character varying(10) not null,
nome character varying(100) not null,
salario numeric(15, 2)
);
insert into funcionarios (codigo, nome, salario) values ('000232', 'Zorrilho', 672.40);
insert into funcionarios (codigo, nome, salario) values ('000239', 'Graxaim', 672.40);
insert into funcionarios (codigo, nome, salario) values ('001431', 'Lebre', 1402.46);
select
trim(leading '0' from codigo) as codigo,
nome,
salario
from funcionarios;
sexta-feira, 30 de dezembro de 2016
sexta-feira, 9 de dezembro de 2016
Listar BUSCAS/SELECTs que já foram feitos a uma tabela.
SELECT sum(seq_scan+idx_scan) AS total_de_leituras
FROM pg_stat_user_tables
WHERE relname=’nome_da_tabela’;
FROM pg_stat_user_tables
WHERE relname=’nome_da_tabela’;
Obs.: Um select com um JOIN considera duas BUSCAS
Lista as tabelas ligadas por chave estrangeira a uma determinada tabela.
SELECT tab_pk.relname AS “tab PK”, tab_fk.relname AS “tab_FK”
FROM pg_class tab_pk
JOIN pg_constraint ON tab_pk.oid=pg_constraint.confrelid
JOIN pg_class tab_fk ON pg_constraint.conrelid=tab_fk.oid
and tab_fk.relname=’cliente’;
FROM pg_class tab_pk
JOIN pg_constraint ON tab_pk.oid=pg_constraint.confrelid
JOIN pg_class tab_fk ON pg_constraint.conrelid=tab_fk.oid
and tab_fk.relname=’cliente’;
work mem
Quando algum processo pesado é executado, por exemplo a geracao de indices do drupal ou consultas que usam muito ORDER BY, um diretorio pgsqltemp será criado caso o uso da memoria setado na variavel WORKMEM seja execedido.
Nestes caso o aconselhável é aumentar - perante monitoramento - o parametro WORK_MEM na sessão em que está executando a query ou rodando os indices.
SET WORK_MEM TO "64MB"
Esse valor é por consulta, se colocar um valor muito alto a máquina vai sentar bonito, procure um valor entre 64 e 128, monitorando o servidor para verificar o impacto.
quinta-feira, 8 de dezembro de 2016
Listar tabelas de um BD em Postgresql
SELECT * FROM pg_catalog.pg_tables
WHERE schemaname NOT IN ('pg_catalog', 'information_schema', 'pg_toast')
ORDER BY schemaname, tablename
WHERE schemaname NOT IN ('pg_catalog', 'information_schema', 'pg_toast')
ORDER BY schemaname, tablename
segunda-feira, 16 de maio de 2016
Postgresql - Formatar CPF com REGEXP_REPLACE
Neste artigo, vamos mostrar 3 exemplos de como utilizar a função REGEXP_REPLACE para formatar o CPF.
1º Exemplo
Para formatar o CPF vamos utilizar a tabela "tb_alunos", exibida na imagem a seguir:


Observe que na função REGEXP_REPLACE:
- Utilizamos parenteses "( )" para separar cada parte da string, neste caso o CPF;
- Utilizamos colchetes "[ ]" para indicar quais os caracteres que iremos utilizar em cada parte, neste caso utilizamos caracteres numéricos de "0" até "9", representados pela expressão 0-9;
- Indicamos dentro das chaves "{}" a quantidade de dígitos que vamos utilizar;
- Utilizamos contra-barra "\" antes de cada parte criada;
Após a execução da sentença, teremos o seguinte resultado:

2º Exemplo
Também podemos substituir a expressão "0-9" que indica a utilização de caracteres numéricos de 0 até 9, pela expressão [:digit:]. O resultado será o mesmo.
Solução

Após a execução da sentença, teremos o seguinte resultado:
3º Exemplo
Para facilitar, podemos substituir a expressão "[[:digit:]]" que indica a utilização de caracteres numéricos de 0 até 9, pela expressão abreviada "\d". O resultado será o mesmo.
Solução
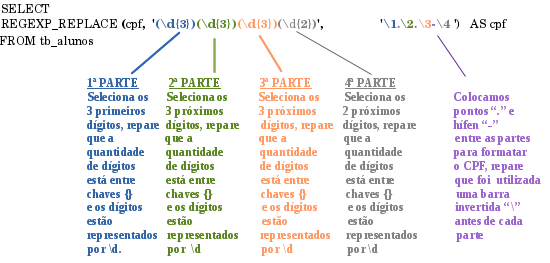
Após a execução da sentença, teremos o seguinte resultado:
sexta-feira, 13 de maio de 2016
COMANDOS PSQL
Além de realizar comandos SQL, o psql também inclui alguns comandos próprios. Por exemplo, para sair do psql, você deve usar o comando \q (note que é uma barra invertida mesmo).
Existem várias opções interessantes, veja alguns exemplos:
- \d: lista as tabelas do banco de dados
- \dv: lista as views do banco de dados
- \di: lista os índices do banco de dados
- \db: lista as tablespaces
- \l: lista os bancos de dados
- \dg: lista as roles existentes (usuários ou grupos)
- \conninfo: apresenta informações sobre a conexão atual
- \h: lista os comandos SQL
- \h comando: apresenta detalhes sobre o comando
- \dn: lista os esquemas do banco de dados
- \c BASE: conecta a base
- \d TABELA: apresenta a estrutura da tabela
Suponha que eu queira fazer uma conexão ao banco de dados BANCO, com o usuário USER, que fica no servidor 10.10.10.10
Para isto, eu deveria usar o comando:
# psql -h 10.10.10.10 -U USER-d BANCO
OU
# psql -U USER
Se vc esquecer o usuário que está usando, basta usar o comando:
#select current_user;
É importante lembrar que o PostgreSQL faz subdivisões no banco de dados, os esquemas. Por padrão, o psql tenta se conectar primeiro a um esquema cujo nome seja igual ao do usuário.
Caso esse esquema não exista, o psql conecta-se ao esquema public. Se você quiser, por exemplo, se conectar ao esquema testes, deverá executar o comando:
#set search_path to TESTE; (conecta ao esquema TESTE)
sábado, 26 de março de 2016
Criando Ranks no Postgres
Vamos supor que você tenha a seguinte tabela:

E você tenha que ordená-la de acordo com os seguintes critérios: a maior média por departamento, seguido de maior nota a, maior nota b e finalmente maior nota c. Fica bem simples se usarmos a cláusula order by:
SELECT department, name, grade_a, grade_b, grade_c
FROM candidates
ORDER BY department, ((grade_a + grade_b + grade_c) / 3) DESC,
grade_a DESC, grade_b DESC, grade_c DESC
Resultado:

Mas agora queremos criar uma qualificação indicando a posição do candidato de acordo com os critérios acima e esta posição deve ser relativa ao departamento que ele pertence, ou seja queremos saber os trê melhores qualificados no departamento "Development" e os três melhores no departamento "Marketing". Talvez muitos já estejam pensando em usar sua linguagem de programação favorita para resolver este problema mas no Postgres temos as Window Functions:
SELECT department, name, grade_a, grade_b, grade_c,
rank() OVER(PARTITION BY department ORDER BY ((grade_a + grade_b + grade_c) / 3) DESC, grade_a DESC, grade_b DESC, grade_c DESC)
FROM candidates
Resultado:

Legal, agora temos um número indicando a posição de cada candidato relativo ao seu departamento. Mas digamos agora que apenas os dois melhores candidatos de cada departamento devem ser retornados. Neste caso a seguinte query deve ser satisfatória:
SELECT * FROM (SELECT department, name, grade_a, grade_b, grade_c,
rank() OVER(PARTITION BY department ORDER BY ((grade_a + grade_b + grade_c) / 3) DESC, grade_a DESC, grade_b DESC, grade_c DESC)
FROM candidates) AS sub_query
WHERE rank < 3
Resultado:


E você tenha que ordená-la de acordo com os seguintes critérios: a maior média por departamento, seguido de maior nota a, maior nota b e finalmente maior nota c. Fica bem simples se usarmos a cláusula order by:
SELECT department, name, grade_a, grade_b, grade_c
FROM candidates
ORDER BY department, ((grade_a + grade_b + grade_c) / 3) DESC,
grade_a DESC, grade_b DESC, grade_c DESC
Resultado:

Mas agora queremos criar uma qualificação indicando a posição do candidato de acordo com os critérios acima e esta posição deve ser relativa ao departamento que ele pertence, ou seja queremos saber os trê melhores qualificados no departamento "Development" e os três melhores no departamento "Marketing". Talvez muitos já estejam pensando em usar sua linguagem de programação favorita para resolver este problema mas no Postgres temos as Window Functions:
SELECT department, name, grade_a, grade_b, grade_c,
rank() OVER(PARTITION BY department ORDER BY ((grade_a + grade_b + grade_c) / 3) DESC, grade_a DESC, grade_b DESC, grade_c DESC)
FROM candidates
Resultado:

Legal, agora temos um número indicando a posição de cada candidato relativo ao seu departamento. Mas digamos agora que apenas os dois melhores candidatos de cada departamento devem ser retornados. Neste caso a seguinte query deve ser satisfatória:
SELECT * FROM (SELECT department, name, grade_a, grade_b, grade_c,
rank() OVER(PARTITION BY department ORDER BY ((grade_a + grade_b + grade_c) / 3) DESC, grade_a DESC, grade_b DESC, grade_c DESC)
FROM candidates) AS sub_query
WHERE rank < 3
Resultado:

Número de conexões PostgreSQL
Comando:
select datname, count(*) from pg_stat_activity group by datname;
Com este comando podemos ver o número de conexões ativas no momento de execução agrupando-as pelo nome do banco de dados.
A saída será semelhante a isso:
datname | count
-----------+-------
testdb | 5
template1 | 1
(2 rows)
A tabela pg_stat_activity também tem outras colunas com outras informações interessantes:
datid - oid do banco de dados
datname - nome do banco de dados
procpid - id do processo
usesysid - OID do usuário
usename - nome do usuário
current_query - query sendo executada atualmente
waiting - status de espera da query
xact_start - horário em que a transação atual começou a executar
query_start - horário em que a query começou a executar
backend_start - horário em que o processo foi iniciado
client_addr - Endereço do cliente
client_port - Porta do cliente
As colunas que mostram informações sobre a query só podem ser vistas pelo super usuário ou se o usuário que estiver vendo as informações for o mesmo do processo que está sendo listado.
select datname, count(*) from pg_stat_activity group by datname;
Com este comando podemos ver o número de conexões ativas no momento de execução agrupando-as pelo nome do banco de dados.
A saída será semelhante a isso:
datname | count
-----------+-------
testdb | 5
template1 | 1
(2 rows)
A tabela pg_stat_activity também tem outras colunas com outras informações interessantes:
datid - oid do banco de dados
datname - nome do banco de dados
procpid - id do processo
usesysid - OID do usuário
usename - nome do usuário
current_query - query sendo executada atualmente
waiting - status de espera da query
xact_start - horário em que a transação atual começou a executar
query_start - horário em que a query começou a executar
backend_start - horário em que o processo foi iniciado
client_addr - Endereço do cliente
client_port - Porta do cliente
As colunas que mostram informações sobre a query só podem ser vistas pelo super usuário ou se o usuário que estiver vendo as informações for o mesmo do processo que está sendo listado.
Assinar:
Postagens (Atom)